processing 1 billion lines within 1 min with Python
16 Mar, 2024
This is my version of solution to 1 BRC written in Python, after this challege ended in Janurary 2024, that’s right i am late to this :(
Wanted to do this in rust, but my Pythonista intrusive thoughts kicked in heavy. So, here I am doing this in Python.
TLDR;
From the naive version which ran in 1248 sec to a chunked based dataframe with multiprocessing version in 200 sec.
Without external libraries ~ 300 sec.
UPDATE: Scroll to bottom and find how I did it within a 1 minute! ~43 seconds :)
Skill issues
When this challenge was posted in Jan’24, I came to know about this just the next day. I was(still am) excited about this.
but there is a problem, the official challenge mentioned about certain hardware requirements, and my system fails to meet up to that. like i got only 8 gigs compared to 16 gigs and 4-core cpu against 8-core (check the Morling's blog for more info)
anyway, let’s do it already
Challenge
- Given 1 billion row text file with the data format
station;temperaturein each row, called measurements file Station is a string and temperature is a float in the range [-100, 100]. (64 bits will suffice) - Output each and every station having minimum, maximum and mean temperatures.
start the game
Firstly, we need to generate the , it’s pretty easy to do it(by refering the original file creation of Morling), given X lines, just need to generate Y amount of data randomly. here is the code
Our input file of 13 gigs is all ready (yeah 13), let’s solve this.
Algorithm
Instead of giving track of each and every temperature in an array and doing processing later, it’s better to just store the bounds of temperatures in single variables.
So, idea is to map each and every station with following values - minimum, maximum, sum of tempertures and there count. and finally just print them aloud and to get mean just do sum/count
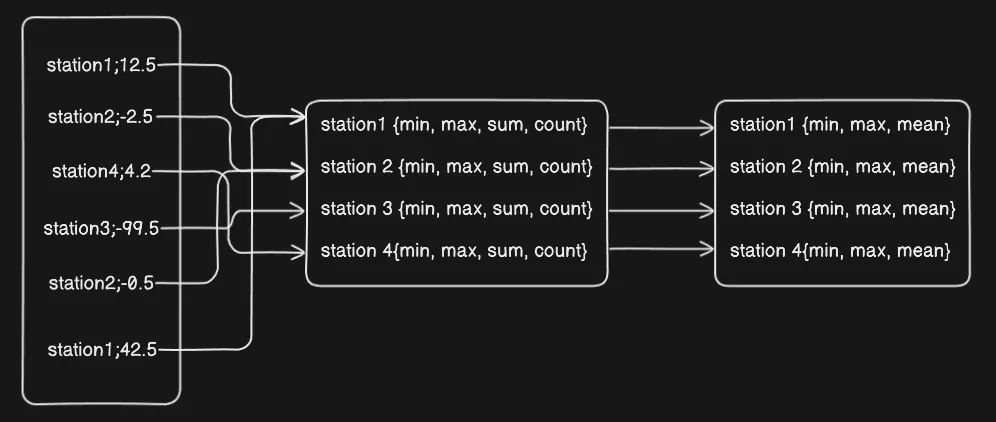
-
version 1: Tried to read the file line-by-line, it worked in just 1657.7 sec, easy 30 mins all cooked. In-buitin file reading generator saves the day
-
version 2: Loading a fat pandas dataframe in memory, reading a 13 gigs file on 8 gigs of memory. and of course it fails.
-
version 2.1 : Load the fat-file dataframe in chunks in memory and process it. let’s say chunks of 1 million rows of 1 billion, for each chunk we calculate it’s 4 values for each and every station. And then at the end merge them up and output the result.
This worked! Now instead of taking 30 mins, it takes 5.95 mins = 357 sec, about 4.6x faster !!
While doing this, i stumbled on polars , a dataframe lib written in rust(surely fast), tried, it’s Fast AF, but lazy loads everything and how wants to lazy load here? Raw is better.
-
version 3: Tried the version 1 with multiprocessing by dividing the file in chunks, process them, following the map/reduce pattern. Runtime now: 361.6 sec
-
version 4: Memory mapping whole file using mmap and processing takes 1286.2 sec
-
version 5: version 4 + parallel processing in chunks using Python’s multiprocessing, took 325.42 sec! 5x faster!
-
version 6: Trying the v2.1 of pandas with multiprocessing, along with panda’s aggregation pipelines brought the runtime to 205 sec! 8x faster!
I think this should be more than enough for this challenge, because we have Python’s GIL as a stop point. I can go a bit more in it, but na not for now.
BTW, running all the above code in PyPy, can bring the final runtime down to 100 sec, like around a minute!
(UPDATE - March 20,2024)
-
version 7 : Reading the file as a buffer of
4MB, makes the file reading fast AF. and then process these buffer asynchronously using polars and multiprocessing these, and calculate a sub-result for every one, and then aggregate them together.And man this small change made it faster, like within a minute, to be exact 43 seconds!!
From what i know it can even go less than 30 seconds with PyPy and further optimzation.

github repository : 1brcpy